Avian solves slow AI inference with a private platform for open-source models. The result: a 3–10x faster, secure API with world-record performance and no data storage.
AI Models & Foundations, Revenue Operations & Forecasting
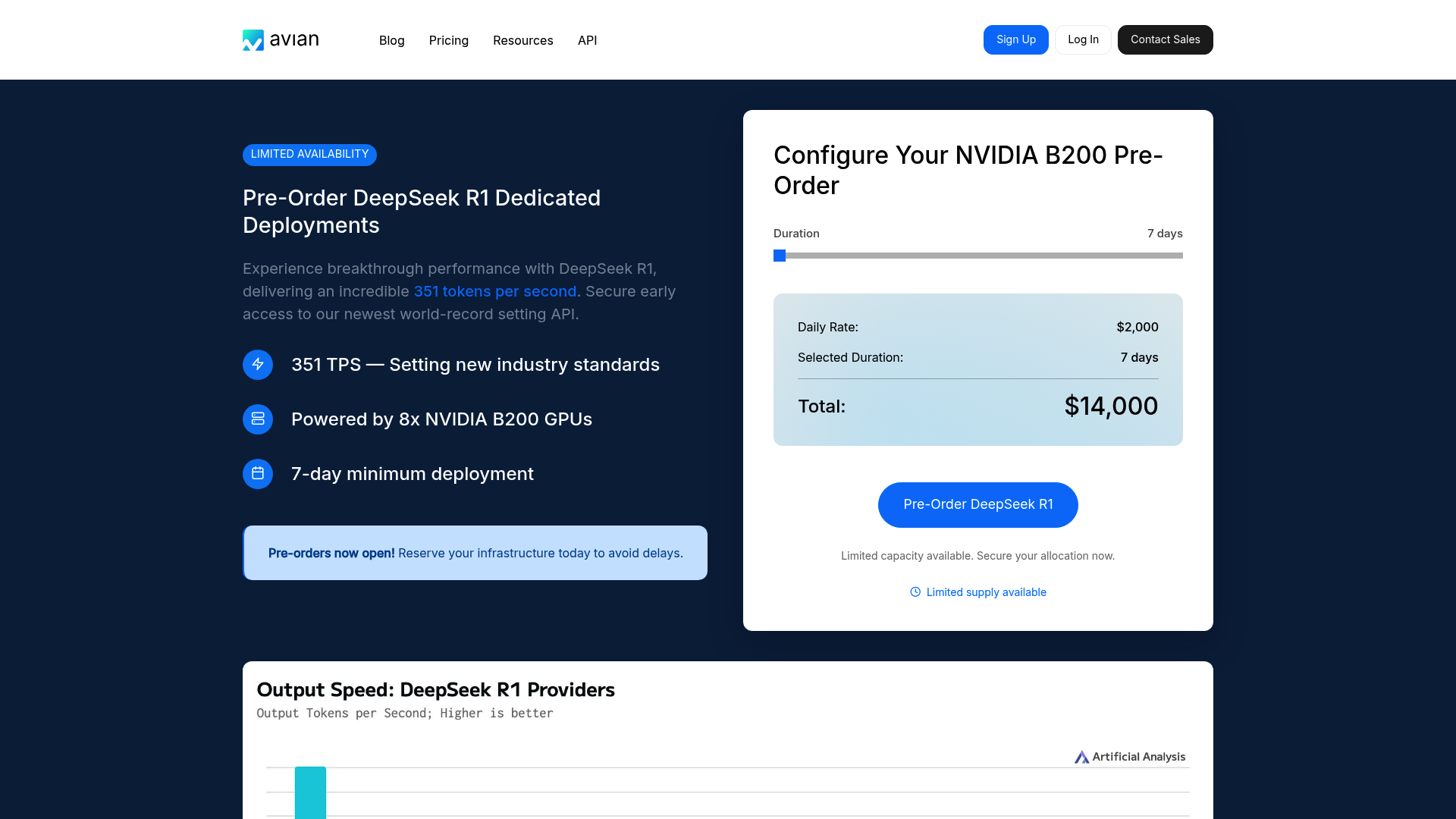
Avian is positioning itself in 2026 as the leading AI research lab for companies seeking maximum speed without compromising on data privacy. With an inference rate of 351 tokens per second for DeepSeek R1, Avian sets new standards. The solution is ideal for companies that want to run open-source models in a secure, SOC 2-compliant Azure environment, with dedicated hardware costs primarily tailored to enterprise budgets. Key Features of the AI Platform: Industry-Leading Inference Speed: At the heart of Avian is its optimization for NVIDIA Blackwell B200 GPUs. By leveraging TensorRT-LLM, the platform achieves speeds that are 3 to 10 times faster than the industry average. This enables near-zero-latency interactions, even with complex models like DeepSeek R1. Enterprise Data Privacy and Compliance: Unlike public API providers, Avian guarantees that no data is permanently stored. The infrastructure is SOC-2 certified and fully compliant with GDPR and CCPA. A special privacy mode for chats provides additional security in regulated industries. OpenAI-compatible API: Integration is incredibly easy, as Avian offers a fully compatible interface to the OpenAI standard. Existing workflows can be migrated to Avian within one minute to benefit from its increased speed and private hosting. Real-time customer support: Thanks to extremely low latency, AI agents can handle complex customer inquiries without any noticeable delay. Generative business intelligence: Avian enables specialized agents to analyze internal data sources without sensitive company data leaving the secure environment. Automated content creation: For media companies that need to produce high volumes of text in seconds, the 351 TPS rate offers a significant productivity advantage. Pricing and value analysis compared: Avian pursues a A dual-track pricing model aimed at professional users: On-demand usage: The entry-level price is approximately $10.00 per NVIDIA B200 hour for flexible workloads. Dedicated instances: For maximum performance, Avian offers dedicated deployments. These start at a daily rate of $2,000 (total: $14,000) with a minimum term of 7 days. Compared to competitors such as standard cloud providers, Avian offers a better price-performance ratio per generated token through specialized optimization, but requires a higher initial budget due to the minimum terms for dedicated hardware.
Key Feature Rating & Critique Ideal for Record-Breaking Inference (351 TPS) Excellent speed, but high cost per GPU hour. Enterprises focused on latency and privacy.
Avian.io positions itself as a leading provider of private AI inference in 2026. With a speed of 351 tokens per second for DeepSeek R1 on NVIDIA B200 hardware, the company sets new standards. It offers a SOC 2-compliant, private environment for open-source models, making it the first choice for privacy-conscious enterprises that want to operate independently of OpenAI. Key Features of Avian: Ultra-High-Speed Inference: By leveraging the NVIDIA Blackwell B200 architecture, Avian achieves inference speeds that are 3-10x faster than standard cloud providers. The optimization for DeepSeek R1 is particularly noteworthy. Enterprise-Grade Privacy: Avian offers full SOC 2, GDPR, and CCPA compliance. Models are hosted in isolated environments, so company data is never used for training.